机器学习要素#
机器学习定义#
机器学习的目标是:通过观测数据(x,y), 让算法从假设集H中自动寻找一个假设函数g(x), 使其尽可能接近真实目标函数f(x).
关键对比:传统编程是“人为定义规则”(如手动设计电影评分公式), 而机器学习是“逆向工程”——从数据(观众评分)反推规则(哪些因素影响评分).
示例:预测电影评分时, 机器学习不依赖“导演名气+演员阵容”等人为设定, 而是通过历史评分数据, 让算法自动发现观众的潜在偏好(如偏爱科幻片或剧情片).
机器学习组成要素#
(X,Y,f,H,A)
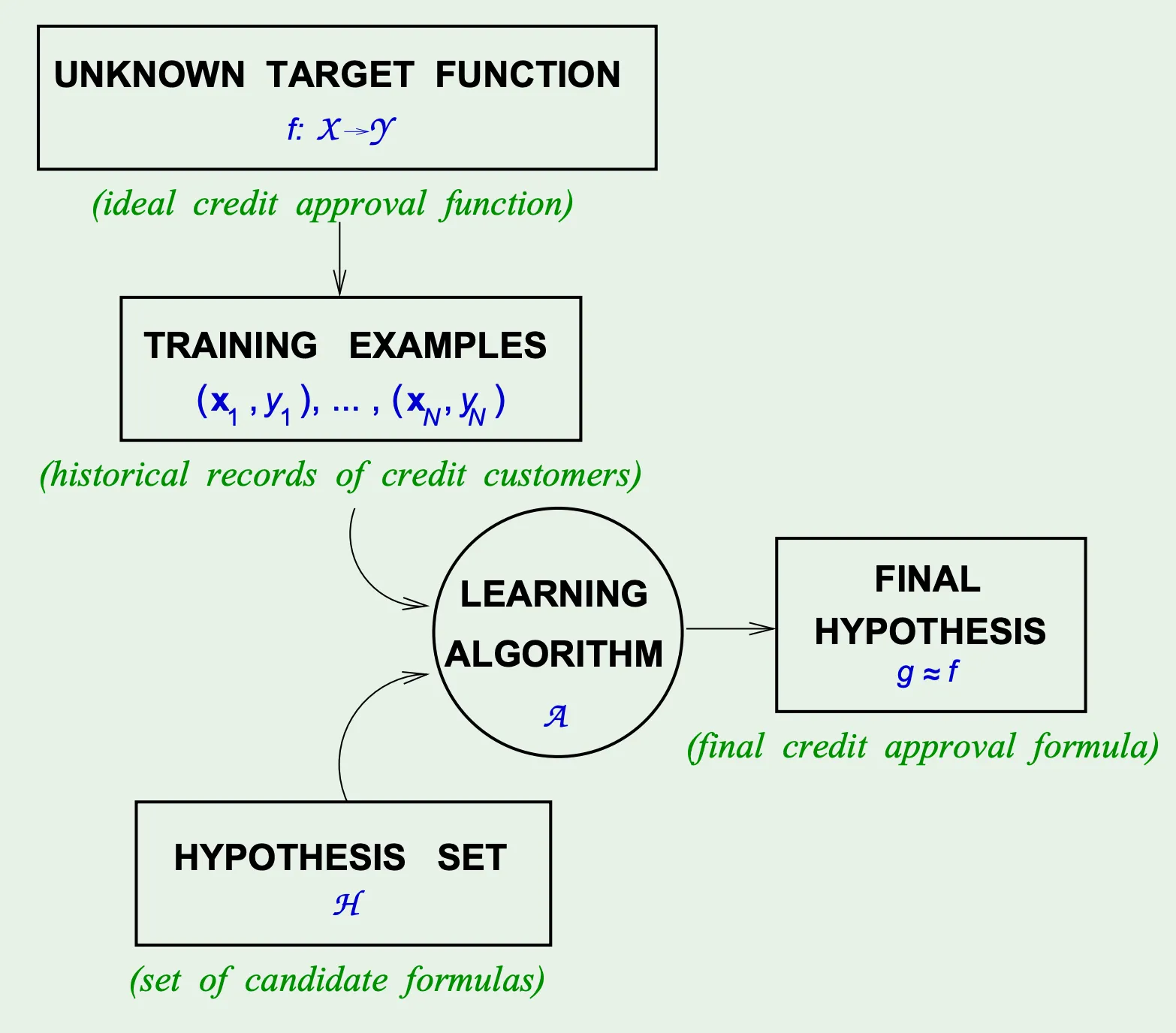
输入空间与输入特征#
输入空间X与输入特征x
定义:x∈X, X 是所有可能输入的特征空间
描述:输入特征向量由算法处理的原始属性构成, 决定模型的感知范围
例子:
电影推荐:X=R2(二维空间), x=[类型编码,时长(分钟)]
具体输入:x=[1,120](1表示科幻片, 120分钟)
输出空间与标签#
输出空间Y与标签y
定义:y∈Y, Y 是目标变量的取值范围
描述:监督学习的目标值, 分为分类(离散)或回归(连续)
例子:
回归任务:Y=[1,5], y=4.5(对应x=[1,120]的电影评分)
分类任务:Y={−1,+1}, y=+1(PLA算法:“推荐/不推荐”的二分类)
数据集#
数据集 D={(xi,yi)}i=1n
目标函数#
目标函数f:X→Y(未知)
假设集和假设函数#
假设集H和假设函数g:X→Y(已知)
用于近似f
数学形式:
例子:
用g(x)=0.8x1−0.01x2+2 预测电影评分, x1(类型)权重为正, x2(时长)权重为负, 对应“科幻片加分、长电影减分”的归纳
感知机
For input x=(x1,⋯,xd) ‘attributes of a customer’
这个集合可以包括:收入, 居住年限等等
Approve credit if i=1∑dwixi>threshold,Deny credit if i=1∑dwixi<threshold.This linear formula h∈H can be written as
h(x)=sign((i=1∑dwixi)−threshold)Introduce an artificial coordinate x0=1:
h(x)=sign(i=0∑dwixi)In vector form, the perceptron implements
h(x)=sign(w⊤x)学习算法#
A:从D到g的优化过程
PLA算法:
步骤:初始化w, 遍历D, 误分类时更新w←w+yixi
终止条件:Ein(g)=0
最小二乘法:
A和H放在一起叫做学习模型.
三大学习#
监督学习:有人教“这是对的”(如父母教孩子“红灯停”).
无监督学习:自己发现“哪些相似”(如孩子把玩具按颜色分类).
强化学习:试错后知道“这样做更好”(如孩子学骑车, 摔了知道要平衡).
监督学习#
定义:用带标签的数据(如“垃圾邮件/正常”“房价100万”), 学输入到输出的映射.
核心:从“已知答案”中模仿规律, 目标是预测新数据的标签.
例子:
分类:售货机识别硬币——提前输入“1元硬币=可乐”“5角硬币=退币”, 学会后根据投币面值吐对应商品.
回归:预测奶茶销量——输入天气温度(28℃/32℃)和历史销量(300杯/500杯), 学温度与销量的关系.
无监督学习#
定义:用无标签数据(如用户消费记录、像素点), 自己找内在结构(分组/模式).
核心:在“没有答案”的情况下, 发现数据的隐藏规律(如相似性、特征压缩).
例子:
聚类:售货机分析投币习惯——收集1000次投币数据(时间、金额), 自动分成“早高峰1元组”和“下午茶5元组”.
降维:压缩商品图片——将1000维像素数据降到50维, 保留“饮料瓶形状”“零食包装颜色”等关键特征.
强化学习#
定义:通过试错互动(行动→环境反馈奖惩), 学最大化长期奖励的策略.
核心:在动态环境中“边做边学”, 奖惩是唯一指导(无直接标签).
例子:
机器人补货:售货机缺货时, 机器人尝试不同路径(左/右/中间), 快到货架+5分, 撞人-3分, 最终学会“绕开人流高峰的最短路径”.
游戏AI:自动玩推箱子, 推到目标+10分, 超时-5分, 通过上万次尝试, 找到“先卡位再推”的最优策略.
参数估计#
矩估计#
设总体 X 的 k 阶原点矩为 μk=E(Xk), 样本 X1,X2,⋯,Xn 的 k 阶原点矩为 Ak=n1∑i=1nXik.
用样本矩估计总体矩:令总体的 k 阶原点矩等于样本的 k 阶原点矩, 即 μk=Ak .
求解参数估计值:假设总体分布中有 m 个未知参数 θ1,θ2,⋯,θm, 可以列出 m 个方程 μkj=Akj(j=1,2,⋯,m), 然后联立求解这 m 个方程, 得到的 θ1,θ2,⋯,θm 的值就是矩估计值 θ^1_ME,θ^2_ME,⋯,θ^m_ME .
如总体均值 μ=E(X), 用样本均值 Xˉ=n1∑i=1nXi 来估计;总体方差 σ2=E((X−E(X))2)=E(X2)−[E(X)]2, 用 S2=n1∑i=1n(Xi−Xˉ)2 (或 Sn2=n−11∑i=1n(Xi−Xˉ)2 , 无偏估计)来估计.
最大似然估计#
假设样本 X1,X2,⋯,Xn 是独立同分布的, 其概率密度函数(或概率质量函数)为 f(x;θ), 其中 θ 是待估计的参数向量.
似然函数: L(θ)=∏i=1nf(Xi;θ)
对数似然函数:为了计算方便, 通常对似然函数取对数得到对数似然函数 lnL(θ)=∑i=1nlnf(Xi;θ)
求解最大似然估计值:通过对对数似然函数求关于 θ 的导数(若 θ 是多维向量, 则求偏导数), 并令导数为 0, 即 ∂θ∂lnL(θ)=0 求解上述方程, 得到的 θ 值就是最大似然估计值 θ^MLE .
贝叶斯估计#
设 θ 是待估计的参数, X 是观测数据.
贝叶斯定理: P(θ∣X)=P(X)P(X∣θ)P(θ)
P(θ∣X) 是后验概率, 表示在观测到数据 X 的条件下, 参数 θ 的概率;
P(X∣θ) 是似然函数, 表示在参数为 θ 的条件下, 观测到数据 X 的概率;
P(θ) 是先验概率, 表示在没有观测到数据 X 之前, 对参数 θ 的概率分布的认识;
P(X) 是证据因子, 是一个与 θ 无关的归一化常数, P(X)=∫P(X∣θ)P(θ)dθ (对于连续型参数)或 P(X)=∑θP(X∣θ)P(θ) (对于离散型参数).
贝叶斯估计值:常见的贝叶斯估计值可以通过后验概率的期望来计算, 即
θ^BE=∫θP(θ∣X)dθ (对于连续型参数)对于离散型参数, 则为 θ^BE=∑θθP(θ∣X) . 此外, 也可以取后验概率的最大值点(即最大后验估计, MAP)作为估计值 .
决策理论#
掌握数据的潜在概率分布
损失(预测差异标准)#
01损失#
- 定义:ℓ(y,z)=1y=z , 即当预测值 z 与真实值 y 相等时(无错误), 损失为 0 ;当预测值 z 与真实值 y 不相等时(有错误), 损失为 1 .
- 适用场景:主要用于分类问题.
平方损失#
- 定义:MSE=n1∑i=1n(yi−y^i)2, 其中yi是真实值, y^i是预测值, n是样本数量.
- 适用场景:常用于回归问题, 能直观反映预测值与真实值的平均偏离程度, 对较大误差惩罚较重.
绝对损失#
- 定义:MAE=n1∑i=1n∣yi−y^i∣.
- 适用场景:也用于回归问题, 对异常值相对不敏感, 能更稳健地反映预测值与真实值的平均误差
交叉熵损失#
- 定义:对于二分类问题, L=−[ylogy^+(1−y)log(1−y^)];对于多分类问题, L=−∑i=1nyilogy^i, 其中y是真实标签, y^是预测的概率分布.
- 适用场景:主要用于分类问题, 尤其是在处理概率输出的模型如逻辑回归、神经网络等中广泛应用, 能很好地衡量两个概率分布之间的差异.
Hinge损失#
- 定义:L=max(0,1−yy^), 常用于支持向量机(SVM)中.
- 适用场景:适用于二分类问题, 它鼓励分类器找到一个能将不同类别数据很好分隔开的决策边界, 使得正确分类的样本距离边界有一定的 margin.
风险(性能评判标准)#
期望风险#
给定一个预测函数f:X→Y、一个损失函数ℓ:Y×Y→R以及一个联合分布p(x,y), 预测函数f的期望风险定义为:
R(f)=E[ℓ(y,f(x))]=∫X×Yℓ(y,f(x))dp(x,y)作用:期望风险反映了模型在整个数据分布上的平均损失情况, 期望风险越低, 通常意味着模型的泛化能力越强, 更有可能在实际应用中取得较好的预测结果.
经验风险(训练误差)#
给定一个预测函数f:X→Y、一个损失函数ℓ:Y×Y→R以及一组训练数据(xi,yi)∈X×Y, 其中i=1,…,n, 预测函数f的经验风险定义为:
R(f)=n1i=1∑nℓ(yi,f(xi))作用:经验风险衡量模型在训练数据上的拟合程度. 训练时, 常通过最小化经验风险调整参数, 让模型适配训练数据. 但单纯追求最小化易引发过拟合, 模型会过度学习噪声与特殊情况, 忽视数据整体分布, 所以无法完全体现模型的泛化能力 .
超额风险#
设模型f的期望风险为R(f), 最优风险(即所有可能模型中最小的期望风险)为R∗, 那么超额风险ΔR定义为:
ΔR=R(f)−R∗作用:超额风险用于评估学习算法所得模型与理论最优模型的差距, 能直观反映模型在泛化能力上的提升空间. 它帮助研究者与工程师判断模型性能, 若超额风险大, 意味着当前模型距最优有较大改进空间, 此时可通过调整模型结构、增加训练数据量或选用更优学习算法等方式优化模型 .
固定设计风险#
输入变量x是固定的, 不随样本变化而随机变动. 假设我们有固定的输入点x1,x2,…,xn, 以及对应的输出yi. 对于预测函数f:X→Y和损失函数ℓ:Y×Y→R, 固定设计风险定义为:
Rfixed(f)=n1i=1∑nE[ℓ(yi,f(xi))]这里的期望是针对输出yi的分布(在给定固定输入xi的条件下).
作用:固定设计风险可评估模型在此特定条件下对输出的预测准确性. 能展现模型在固定输入环境中的性能, 助力在该场景下筛选合适模型、判断模型对特定输入的适应性. 并且, 分析固定设计风险随模型参数等因素的变化, 可优化模型在此场景下的性能 .
随机设计风险#
输入变量x是随机的, 服从某个分布p(x). 对于预测函数f:X→Y、损失函数ℓ:Y×Y→R以及联合分布p(x,y), 随机设计风险定义为:
Rrandom(f)=Ex[Ey∣x[ℓ(y,f(x))]]=∫X(∫Yℓ(y,f(x))dp(y∣x))dp(x)其中Ey∣x表示在给定x条件下对y的期望, Ex表示对x的期望.
作用:随机设计风险可评估模型对随机输入的泛化能力, 判断其能否适应不同输入并维持良好预测性能. 鉴于真实环境数据多具随机性, 这对模型实际应用意义重大. 它有助于筛选在随机输入下表现最佳的模型, 还能评估模型在复杂多变现实环境中的可靠性与稳定性.
贝叶斯风险#
将未知参数视为随机变量, 强调基于已有信息(先验知识)和观测数据进行推断. 在贝叶斯体系里, 先验知识通过先验分布 P(θ) 体现, 它代表在未接触观测数据之前, 我们对参数 θ 的不确定性认知. 当获取到观测数据 X 后, 运用贝叶斯定理
P(θ∣X)=P(X)P(X∣θ)P(θ)
更新先验分布, 从而得到后验分布 P(θ∣X). 其中, P(X∣θ) 为似然函数, 描述在参数为 θ 时观测到数据 X 的概率;P(X) 作为证据因子, 用于对后验分布进行归一化处理. 通过这种方式, 我们能依据不断积累的信息, 持续更新对参数的认知.
先验估计#
先验估计即确定先验分布 P(θ) 的过程. 先验分布的设定可基于过往经验、领域专业知识或合理假设.
例如, 在估计一枚硬币正面朝上的概率 θ 时, 若毫无额外信息, 我们可能采用均匀分布作为先验分布, 意味着在观测数据前, 认为 θ 取任何值的可能性均等.
若已知该硬币是正常硬币, 大概率会将先验分布设定为以 0.5 为中心的较为集中的分布, 反映对硬币正面朝上概率接近 0.5 的先验认知.
后验估计#
后验估计是在依据观测数据 X 得到后验分布 P(θ∣X) 后, 对参数 θ 进行估计的过程. 常见方法主要有两种:
最大后验估计(MAP):选取后验分布中概率最大的参数值作为估计值.
基于后验期望的估计:计算参数 θ 在给定后验分布下的期望值作为估计值. 后验估计融合了先验信息与观测数据, 相较于单纯的先验估计, 能更精准反映参数的真实状况.
在贝叶斯框架下, 结合数据的联合分布 p(x,y), 以及预测函数 f:X→Y 和损失函数 ℓ:Y×Y→R, 贝叶斯风险的定义为:
R∗=Ex′∼dpx(x′)z∈YinfE(ℓ(y,z)∣x=x′)作用
评估性能:作为评估模型性能的基准, 对比实际模型风险与贝叶斯风险, 基于贝叶斯框架对不确定性的处理, 判断模型性能提升空间.
指导选型:模型选择时, 优先考虑风险接近贝叶斯风险的模型, 因其更趋近理论最优, 泛化能力和预测准确性更佳, 能更好利用先验与数据信息.
助力改进:模型改进时, 若模型风险远高于贝叶斯风险, 可重新审视先验分布设定或调整模型结构, 以优化数据拟合效果, 因为先验分布影响后验推断和预测风险
贝叶斯预测器(最佳预测函数)#
利用条件期望及全期望公式:
R(f)R(f)=E[ℓ(y,f(x))]=E[E(ℓ(y,f(x))∣x)]=Ex′∼dp(x)[E(ℓ(y,f(x))∣x=x′)]=∫X(E(ℓ(y,f(x))∣x=x′))dp(x′)给定对于任意x′∈X 的条件分布, 即y∣x=x′, 为任意z∈Y 定义条件风险:
r(z∣x′)=E(ℓ(y,z)∣x=x′)由此可得
R(f)=E(r(f(x)∣x))=Ex′∼dp(x)[r(f(x′)∣x′)]=∫Xr(f(x′)∣x′)dp(x′)期望风险在贝叶斯预测器f∗:X→Y 处达到最小, 对于所有x′∈X,
f∗(x′)∈argz∈YminE(ℓ(y,z)∣x=x′)=argz∈Yminr(z∣x′)贝叶斯风险R∗ 是所有贝叶斯预测器的风险, 且等于:
R∗=Ex′∼dpx(x′)z∈YinfE(ℓ(y,z)∣x=x′)常用的贝叶斯预测器#
0 - 1损失:
- 对于Y={0,1} 和ℓ(y,z)=1y=z, 贝叶斯预测器满足:
f∗(x′)∈argz∈{0,1}minP(y=z∣x=x′)=argz∈{0,1}min1−P(y=z∣x=x′)=argz∈{0,1}maxP(y=z∣x=x′)- 记η(x′)=P(y=1∣x=x′), 如果η(x′)>1/2, f∗(x′)=1;而如果η(x′)<1/2, f∗(x′)=0. 当η(x′)=1/2 时, 结果无关紧要.
- R∗=E[min{η(x),1−η(x)}], 一般来说它严格为正(除非η(x)∈{0,1} 几乎必然成立, 即y 是x 的确定性函数).
- 当k≥2 时Y={1,…,k}, 此时f∗(x′)∈argmaxi∈{1,…,k}P(y=i∣x=x′) .
平方损失:
- 对于Y=R 和ℓ(y,z)=(y−z)2, 贝叶斯预测器满足:
f∗(x′)∈argz∈RminE[(y−z)2∣x=x′]=argz∈Rmin{E[(y−E(y∣x=x′))2∣x=x′]+(z−E(y∣x=x′))2}- 得到条件期望f∗(x′)=E(y∣x=x′) .
绝对损失:
- 对于Y=R 和ℓ(y,z)=∣y−z∣, 贝叶斯预测器满足: f∗(x′)∈argminz∈RE[∣y−z∣∣x=x′]
- 可以证明此时f∗(x′) 是条件中位数, 即f∗(x′) 满足P(y≤f∗(x′)∣x=x′)≥21 且P(y≥f∗(x′)∣x=x′)≥21 .
Hinge损失:
- 对于二分类问题Y={−1,1}, Hinge损失函数定义为ℓ(y,z)=max(0,1−yz) .
- 贝叶斯预测器f∗(x′)∈argminz∈{−1,1}E[max(0,1−yz)∣x=x′] .
- 记p=P(y=1∣x=x′), 1−p=P(y=−1∣x=x′), 则E[max(0,1−yz)∣x=x′]=pmax(0,1−z)+(1−p)max(0,1+z) .
- 当p>21 时, f∗(x′)=1;当p<21 时, f∗(x′)=−1;当p=21 时, 选择z=1 或z=−1 对风险没有影响 .
通过对不同损失函数下贝叶斯预测器的分析, 我们可以根据具体问题选择合适的损失函数和预测器, 以最小化期望风险.
统计学习理论#
学习理论的目标是为模型在未见数据上的性能提供一定的保障. 假设数据Dn(dp)={(x1,y1),…,(xn,yn)} 是从分布族P 中某个未知分布dp 进行独立同分布(i.i.d.)采样得到的观测值.
目标是找到这样的算法A :A 是一个从Dn(dp)(对于任意n)到一个从X 到Y 的函数的映射, 风险取决于概率分布dp∈P, 表示为Rdp(f) .
性能度量#
期望误差#
定义:E[Rdp(A(Dn(dp)))], 其中期望是关于训练数据的.
一致性判断:对于分布dp, 如果当n趋于无穷时, E[Rdp(A(Dn(dp)))]−Rdp∗趋于0, 则称算法A在期望上是一致的.
“可能近似正确”(PAC)学习:对于给定的δ∈(0,1)和ε>0:
P([Rdp(A(Dn(dp)))−Rdp∗]≤ε)≥1−δ关键在于找到尽可能小的ε(通常是δ的函数). PAC一致性的概念是指, 对于任意ε>0, 对于每个n 都有这样一个不等式成立, 并且存在一个趋于0的序列δn .
没有免费的午餐定理#
定理(固定n): 考虑带有0 - 1损失的二分类问题, 其中X 是无限集. 设P 表示X×{0,1} 上所有概率分布的集合. 对于任意n>0 和学习算法A,
dp∈PsupE[Rdp(A(Dn(dp)))]−Rdp∗≥1/2该定理指出, 不存在一个能在所有分布上都最优运行的学习算法. 也就是说, 在机器学习中, 没有假设的情况下学习是不可能的. 这打破了我们对于找到一个通用的完美算法的幻想.
证明的主要思路:
(a) 构造一个支撑在N 中k 个元素上的概率分布, 其中k 相较于固定的n 很大, 并证明n 个标签的信息并不能保证在所有k 个元素上都表现良好;
(b) 通过与由随机参数得到的性能进行比较来选择该分布的参数(下面的向量r).
定理 (误差序列): 考虑带有0 - 1损失的二分类问题, 其中X 是无限集. 设P 表示X×{0,1} 上所有概率分布的集合. 对于任意趋于0 的递减序列an , 且满足a1≤1/16, 对于任意学习算法A , 存在dp∈P , 使得对于所有n≥1:
E[Rdp(A(Dn(dp)))]−Rdp∗≥an证明: 设k 为正整数. 不失一般性, 我们可以假设N⊂X.
给定r∈{0,1}k, 我们在(x,y) 上定义联合分布dp, 使得对于
j∈{1,…,k}, P(x=j,y=rj)=1/k;也就是说, 对于x, 我们从k 个元素中均匀随机地选择一个, 然后y 被选定为y=rx. 因此贝叶斯风险为0(因为存在确定性关系):Rdp∗=0.
记fDn=A(Dn(dp)) 为分类器, S(r)=E[Rdp(fDn)] 为期望风险, 我们想要关于r∈{0,1}k 最大化S(r);这个最大值大于r 上任意分布dq 下S(r) 的期望, 特别是均匀分布(每个rj 是独立无偏的伯努利变量). 那么
r∈{0,1}kmaxS(r)≥Er∼dq(r)S(r)=P(fDn(x)=y)=P(fDn(x)=rx)因为x 几乎必然在{1,…,k} 中, 且y=rx 几乎必然成立. 注意我们是关于x1,…,xn,x 和r 取期望(它们相互独立).
Er∼dq(r)S(r)=E[P(fDn(x)=rx∣x1,…,xn,rx1,…,rxn)]≥E[P(fDn(x)=rx & x∈/{x1,…,xn}∣x1,…,xn,rx1,…,rxn)]=E[21P(x∈/{x1,…,xn}∣x1,…,xn,rx1,…,rxn)]根据全期望公式根据概率的单调性因为P(fDn(x)=rx∣x∈/{x1,…,xn},x1,…,xn,rx1,…,rxn)=1/2(在x 未被观测到的情况下, 标签x=rx 为0 或1 的概率相同). 因此,
Er∼dq(r)S(r)≥21P(x∈/{x1,…,xn})=21E[i=1∏nP(xi=x∣x)]=21(1−1/k)n给定n, 我们可以让k 趋于无穷来得出结论.
评估方法#
交叉验证#
K折交叉验证:将数据集分为K个互不重叠子集, 轮流以一个子集为测试集, 其余为训练集, 重复K次, 取平均评估模型.
留一交叉验证(LOOCV):K等于样本总数, 每次用一个样本做验证, 其余做训练, 遍历所有样本
分层交叉验证:适用于分类任务, 保证每个折内类别分布与整体一致, 避免类别失衡影响评估.
时间序列交叉验证:用于时间序列数据, 按时间顺序划分, 防止数据泄漏, 保证评估真实性.
嵌套交叉验证:包含内外层, 外层评估模型泛化性, 内层用于超参数优化.
| 取出测试集, 剩下的(A,B,C,D,E)当训练集和验证集, 第一次A当验证, BCDE训练. 第二次B当验证, ACDE训练… |
|---|
 |

