

1. 机器学习定义
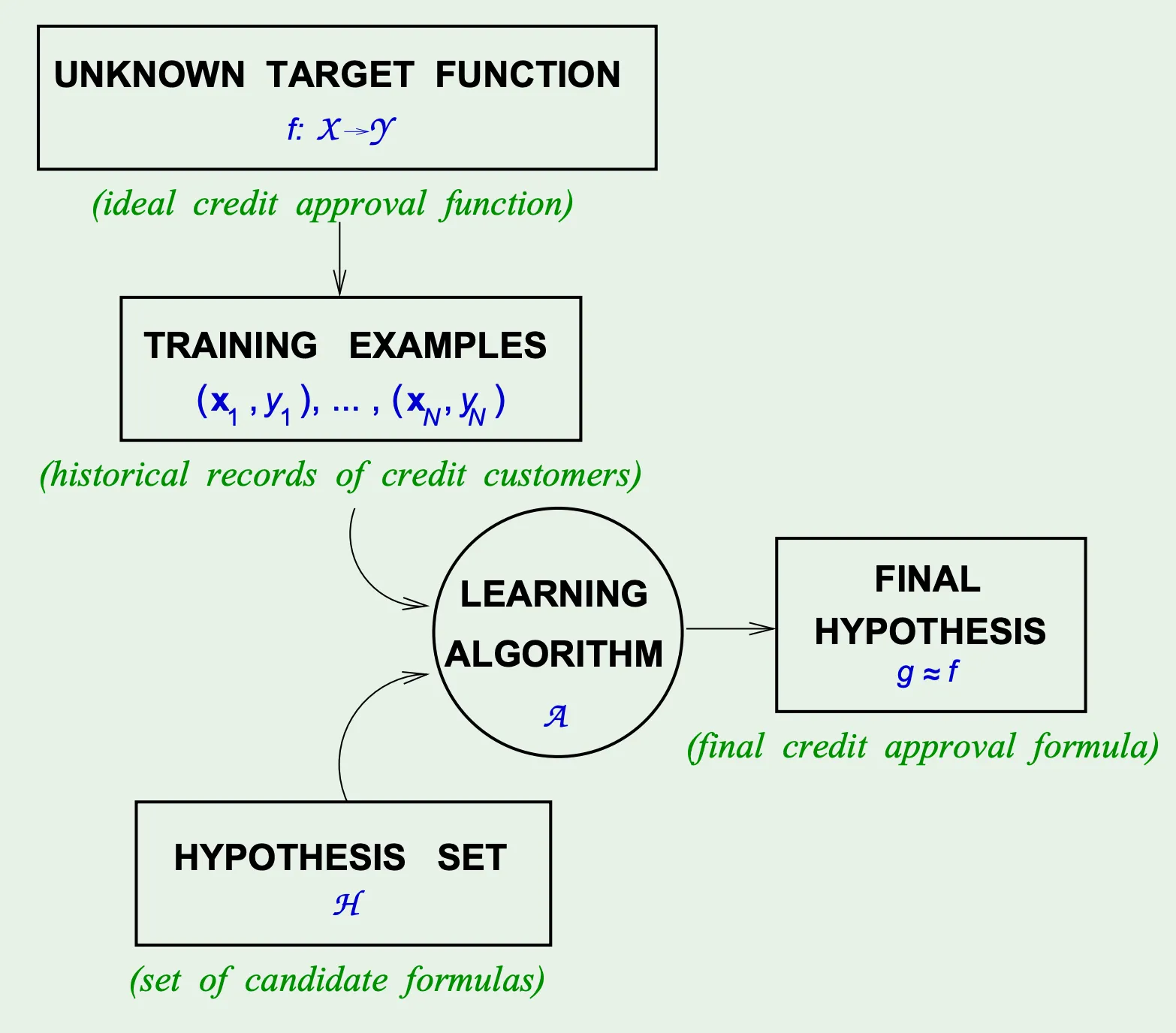
机器学习的目标是:通过观测数据,让算法从假设集中自动寻找一个假设函数,使其尽可能接近真实目标函数.
关键对比:传统编程是“人为定义规则”(如手动设计电影评分公式),而机器学习是“逆向工程”——从数据(观众评分)反推规则(哪些因素影响评分).
示例:预测电影评分时,机器学习不依赖“导演名气+演员阵容”等人为设定,而是通过历史评分数据,让算法自动发现观众的潜在偏好(如偏爱科幻片或剧情片).
2. 机器学习组成要素
(1). 输入空间与输入特征
定义:, 是所有可能输入的特征空间
描述:输入特征向量由算法处理的原始属性构成,决定模型的感知范围
例子:
电影推荐:(二维空间),
具体输入:(1表示科幻片,120分钟)
(2). 输出空间与标签
定义:, 是目标变量的取值范围
描述:监督学习的目标值,分为分类(离散)或回归(连续)
例子:
回归任务:,(对应的电影评分)
分类任务:,(PLA算法:“推荐/不推荐”的二分类)
(3). 数据集
定义:从真实分布 独立同分布采样的训练集
例子:
生成方式: 由 生成并添加噪声(如电影评分受“观众情绪”噪声影响)
规模影响: 时PLA可能过拟合, 时更接近
(4). 目标函数(未知)
定义:数据生成的真实映射关系,无法显式获取
例子:
人工生成数据,算法通过多项式拟合尝试逼近
(5). 假设集和建设函数(已知)
用于近似
数学形式:
线性分类:(PLA算法)
线性回归:()
例子:
用 预测电影评分,(类型)权重为正,(时长)权重为负,对应“科幻片加分、长电影减分”的归纳
The perceptron hypothesis
For input ‘attributes of a customer’
这个集合可以包括:收入,居住年限等等
This linear formula can be written as
Introduce an artificial coordinate :
In vector form, the perceptron implements
(6). 学习算法
从到的优化过程
PLA算法:
步骤:初始化,遍历,误分类时更新
终止条件:
最小二乘法:
目标:
解:
和放在一起叫做学习模型.
3. 三大学习: 监督学习、非监督学习、强化学习
监督:有人教“这是对的”(如父母教孩子“红灯停”).
无监督:自己发现“哪些相似”(如孩子把玩具按颜色分类).
强化:试错后知道“这样做更好”(如孩子学骑车,摔了知道要平衡).
(1)、监督学习
定义:用带标签的数据(如“垃圾邮件/正常”“房价100万”),学输入到输出的映射。
核心:从“已知答案”中模仿规律,目标是预测新数据的标签。
例子:
分类:售货机识别硬币——提前输入“1元硬币=可乐”“5角硬币=退币”,学会后根据投币面值吐对应商品。
回归:预测奶茶销量——输入天气温度(28℃/32℃)和历史销量(300杯/500杯),学温度与销量的关系。
(2)、无监督学习
定义:用无标签数据(如用户消费记录、像素点),自己找内在结构(分组/模式)。
核心:在“没有答案”的情况下,发现数据的隐藏规律(如相似性、特征压缩)。
例子:
聚类:售货机分析投币习惯——收集1000次投币数据(时间、金额),自动分成“早高峰1元组”和“下午茶5元组”。
降维:压缩商品图片——将1000维像素数据降到50维,保留“饮料瓶形状”“零食包装颜色”等关键特征。
(3)、强化学习
定义:通过试错互动(行动→环境反馈奖惩),学最大化长期奖励的策略。
核心:在动态环境中“边做边学”,奖惩是唯一指导(无直接标签)。
例子:
机器人补货:售货机缺货时,机器人尝试不同路径(左/右/中间),快到货架+5分,撞人-3分,最终学会“绕开人流高峰的最短路径”。
游戏AI:自动玩推箱子,推到目标+10分,超时-5分,通过上万次尝试,找到“先卡位再推”的最优策略。